
Key Highlights:
- 5× Faster Decisions: Data-driven companies make decisions five times faster than competitors using visualization (Bain & Company)
- $1.28M Hidden Losses: One client bled money for 8 months on a quality issue—data existed, but without visualization, insights remained ignorable
- 53% Data Waste: Over half of business leaders admit collected data goes unanalyzed without effective visualization (Salesforce)
- $12.9M Annual Cost: Poor data quality costs organizations an average of $12.9 million yearly (Gartner)
- Real Implementation Costs: $33K-75K (small business) to $1M-3.6M+ (enterprise) Year 1—we break down exactly where money goes
- 40% Failure Rate: Poor data quality causes most visualization project failures—not technology issues
I’ll never forget the moment a manufacturing client’s CFO realized they’d been hemorrhaging $40,000 weekly for eight consecutive months. The issue? A systemic quality control problem that eventually cost them $1.28 million. The most frustrating part wasn’t that the problem existed—it was that the data proving it existed had been sitting in their databases the entire time.
Within 30 seconds of visualizing that same data on a control chart, the pattern became undeniable. As data analyst Alberto Cairo observes: “The purpose of visualization is insight, not pictures.”
This scenario isn’t unusual. Salesforce research shows 53% of business leaders admit much of their collected data goes completely unanalyzed. Meanwhile, Bain & Company reveals that companies effectively leveraging visualization make decisions five times faster than competitors and are three times more likely to execute successfully.
But here’s what most articles won’t tell you: visualization tools alone don’t deliver these results. After implementing systems across retail, finance, and manufacturing, I’ve learned that success requires understanding the technical realities, predictable pitfalls, and strategic approaches that separate transformative deployments from expensive shelf-ware.
Quick Answer
Big data visualization converts massive, complex datasets into interactive charts and dashboards humans can quickly comprehend. It delivers 5× faster decision-making, reveals hidden patterns across millions of data points, enables real-time monitoring, reduces fraud/operational risks, and democratizes insights organization-wide—transforming data overload into competitive advantage.

What Is Big Data Visualization?
Big data visualization represents massive, complex datasets through interactive charts, graphs, maps, and dashboards that make patterns immediately visible. But the “big data” qualifier matters—this isn’t just regular data visualization at a larger scale.
The Three V’s that define big data visualization:
Volume: Beyond Traditional Tool Capacity
You’re handling terabytes to petabytes of information. At this scale, traditional visualization tools literally cannot process the data. You need:
- In-memory computing engines (like Spark) that distribute processing across clusters
- Data aggregation strategies that pre-calculate metrics rather than computing on-demand
- Progressive rendering techniques that load visualizations incrementally
- Server-side processing rather than client-side rendering to avoid browser crashes
Velocity: Real-Time Processing Requirements
You’re processing real-time or near-real-time streaming data as events occur. This requires:
- Stream processing frameworks (Kafka, Flink) that handle continuous data flows
- Understanding latency trade-offs: true real-time (<1 second) vs. near-real-time (1-10 seconds) vs. micro-batch (minutes)
- Strategic decisions about which metrics actually need real-time updates vs. hourly refreshes
- Balancing refresh frequency against system performance and infrastructure costs
Variety: Multi-Source Integration Complexity
You’re integrating structured databases, unstructured text, sensor feeds, images, and multimedia simultaneously. This means:
- Building data pipelines that normalize disparate formats
- Handling schema-on-read vs schema-on-write approaches
- Managing data quality across sources with different reliability levels
- Creating unified semantic layers so users don’t need to understand technical complexity
Reality Check:
A retail client wanted “real-time dashboards” for 2,000 stores. Their POS systems synced every 15 minutes, inventory updated hourly, social media monitoring refreshed every 5 minutes. We built dashboards with data freshness timestamps for each metric—transparency that built trust rather than creating illusions of impossible real-time omniscience.
Building this infrastructure requires robust data engineering. Learn more about creating scalable data pipelines and ETL processes that handle big data volumes efficiently.
The 7 Advantages (With Technical Reality)
1. Dramatically Faster Decision-Making (But Only If You Design for It)
The often-cited statistic about the human brain processing visual information 60,000 times faster than text is technically accurate but misleadingly simplistic. The reality is more nuanced.
What actually happens neurologically:
- Visual cortex processes simple patterns (color, shape, position) pre-attentively—meaning before conscious attention
- Complex insights still require cognitive processing, but visualization frontloads pattern recognition to the unconscious visual system
- This works only if you choose appropriate chart types that align with natural perceptual capabilities
Bain research shows data-driven firms make decisions 5× faster and execute 3× more reliably. But when I dig into successful implementations, the speed advantage comes from specific design choices:
What Works:
- Pre-aggregated KPIs: Executives see three critical metrics immediately—not 47 metrics requiring interpretation
- Exception-based alerts: Dashboards highlight what’s wrong rather than forcing users to hunt for problems
- Drill-down paths: Users can investigate anomalies without calling IT
- Contextual comparisons: Current performance shown against targets, historical trends, and peer benchmarks simultaneously
What Fails:
- Cluttered dashboards with 20+ visualizations fighting for attention
- Missing context (Is 47% good? Compared to what?)
- Update latency without indicators (Users don’t know if data is current or stale)
- Requiring multiple dashboard clicks to answer simple questions
Real Example:
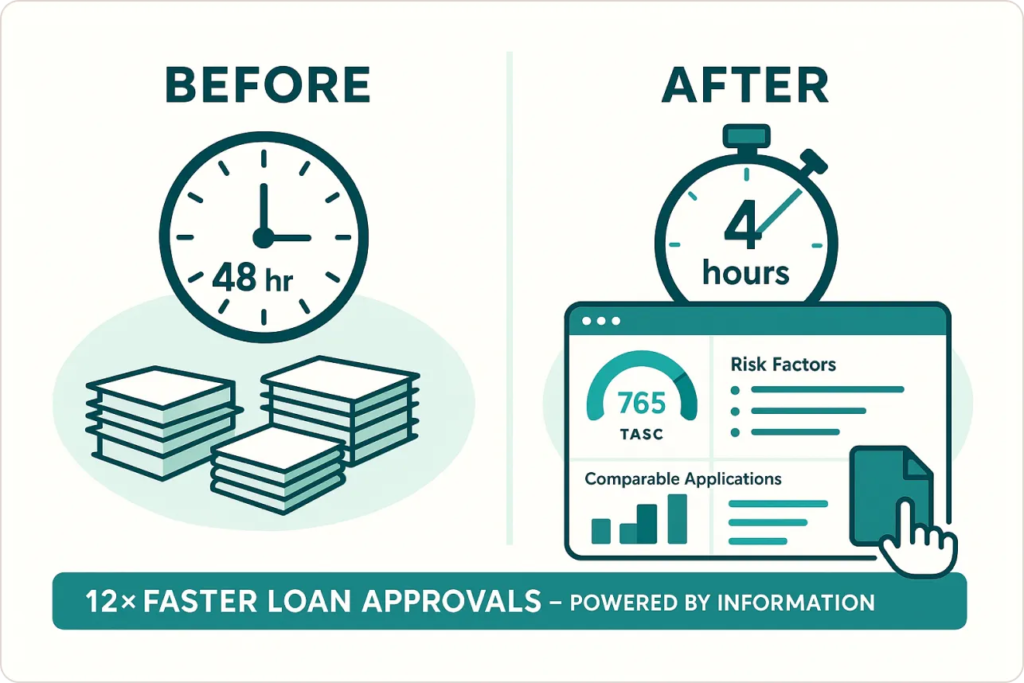
A financial services client reduced loan approval decisions from 48 hours to 4 hours with a risk dashboard displaying credit scores with visual indicators, comparable applications, specific risk factors, and one-click document access. The 12× improvement came from thoughtful information architecture, not technology alone.
This is why modern data analytics strategies emphasize user-centered design over feature accumulation.
2. Uncover Hidden Patterns (If You Know Where to Look)
Deloitte research confirms visual analytics “unlocks previously invisible patterns.” But this advantage has significant caveats most articles ignore.
The Technical Challenge: Pattern discovery requires combining datasets that weren’t designed to work together.
Data integration hurdles:
- Mismatched timestamps (one system logs by second, another by hour)
- Inconsistent granularity (daily sales vs. weekly inventory counts)
- Different entity definitions (what counts as a “customer” varies by system)
- Quality disparities (90% complete data from System A vs. 60% from System B)
3. Real-Time Monitoring (Understanding the Technical Reality)
“Real-time” is the most misunderstood term in big data visualization. Let me define what different organizations actually mean:
| Latency Type | Response Time | Use Cases | Technical Requirements | Typical Cost |
|---|---|---|---|---|
| True Real-Time | <1 second | Algorithmic trading, fraud detection, industrial process control | Stream processing (Kafka, Flink), in-memory databases, WebSocket connections | $50K-500K+ implementation |
| Near Real-Time | 1-60 seconds | Social media monitoring, website analytics, delivery tracking | Micro-batch processing, caching layers, polling mechanisms | $10K-100K implementation |
| Fast Batch | 1-15 minutes | Retail inventory, customer service queues, manufacturing throughput | Scheduled ETL jobs, incremental updates, efficient queries | $5K-50K implementation |
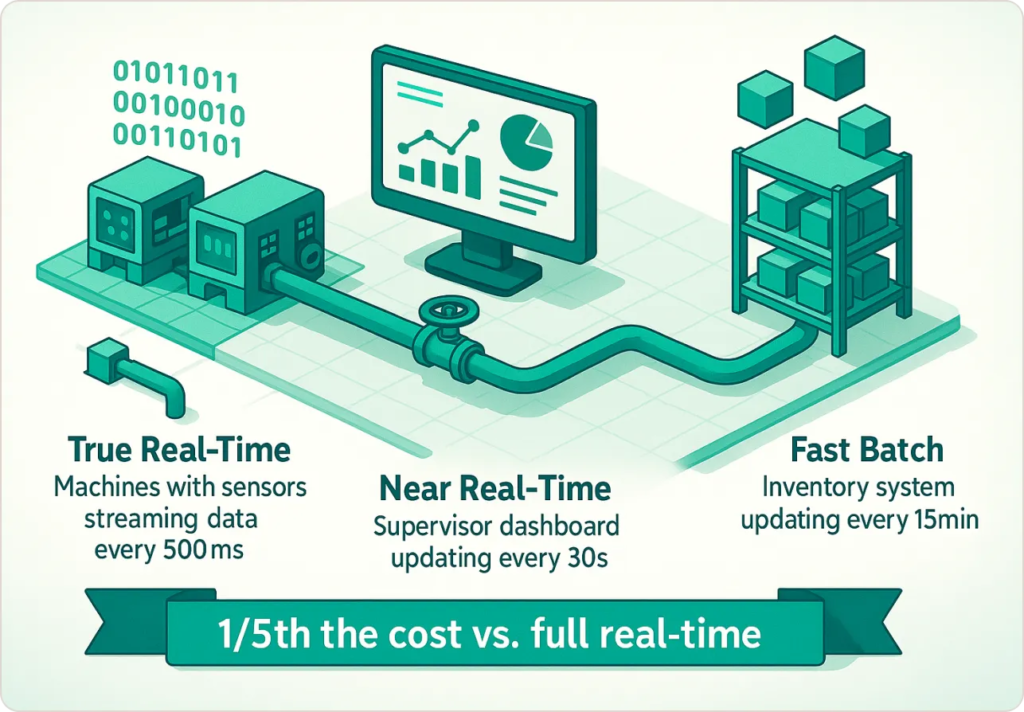
Common Mistake: Organizations spend 10× more building “real-time” systems when their business processes can only respond every 30 minutes. A retail store manager can’t restock shelves every 60 seconds—hourly inventory visibility is sufficient.
Manufacturing Example:
A factory implemented three tiers: (1) True real-time (500ms) for machine temperature/pressure preventing catastrophic failure; (2) Near real-time (30-second) for production throughput allowing supervisor adjustments; (3) Fast batch (15-minute) for inventory and workforce allocation. They achieved meaningful visibility for 1/5th the cost of making everything “real-time.”
4. Error Detection and Risk Management (With Specific Techniques)
Every organization talks about “catching errors early.” Few discuss how visualization actually enables this.
The Technical Approaches That Work:
Statistical Process Control (SPC) Charts:
- Plot metrics with statistically-derived control limits
- Flag when data points fall outside 2-3 standard deviations
- Distinguish true anomalies from normal variation
- Works for: Manufacturing quality, transaction processing, system performance
Time-Series Anomaly Detection:
- Use historical patterns to predict expected ranges
- Highlight deviations from forecasted values
- Account for seasonality, trends, cyclical patterns
- Works for: Sales forecasting, demand planning, capacity management
Multi-Dimensional Outlier Visualization:
- Scatter plots showing relationships between variables
- Color/size encoding to add additional dimensions
- Interactive filtering to isolate suspicious patterns
- Works for: Fraud detection, credit risk, customer behavior analysis
Financial Services: A bank’s fraud detection dashboard combining transaction patterns, geographic locations, velocity checking, and merchant categories increased detection rate from 67% to 91%, reduced detection time from 4.3 days to 14 hours, and cut review time from 8-12 minutes to 2-3 minutes per case.
Annual impact: Prevented additional $3.7M in fraud losses while reducing false positive costs by $180K.
Financial institutions facing similar challenges often benefit from specialized financial analytics solutions that combine visualization with industry-specific compliance requirements.
5. Data Storytelling and Executive Communication (The Framework That Works)
Bernard Marr accurately notes: “Data visualization is not just about making data pretty—it’s about making data actionable and accessible to decision-makers who need to act quickly.” (Source)
But “data storytelling” has become such a buzzword that few organizations understand how to actually do it. Here’s the framework I use:
The Three-Act Structure for Data Presentations:
Act 1: The Setup (What’s the context?)
- Where are we now? (Current state visualization)
- Why does this matter? (Business impact quantified)
- What’s at stake? (Risk or opportunity framing)
Act 2: The Conflict (What’s the problem or opportunity?)
- Show the gap between current and desired state
- Reveal the pattern, trend, or anomaly
- Explain why standard approaches failed
Act 3: The Resolution (What should we do?)
- Recommended actions with expected outcomes
- Risks of inaction quantified
- Resource requirements transparent
Executive Presentation: A retail client secured board approval for $2.3M supply chain investment by showing: carrying costs increased 23% while satisfaction decreased 12%, decisions made with 72-hour-old data, competitor benchmarks, and $4.1M annual savings projection with 6.7-month payback. The board voted unanimously—not because visuals were beautiful, but because the business case was irrefutable.
6. Customer Insights and Service Innovation (With Segmentation Strategies)
75% of businesses use data to drive innovation—but the gap between collection and insight remains enormous. The challenge isn’t data volume; it’s analysis scalability.
Visualization Techniques That Solve This:
Cohort Analysis Visualization:
- Track groups of customers acquired in the same period
- Compare retention, lifetime value, engagement over time
- Identify which acquisition channels produce best customers
Customer Journey Mapping:
- Visualize paths customers take from awareness→purchase→retention
- Identify drop-off points and conversion barriers
- Highlight successful paths to replicate
RFM (Recency, Frequency, Monetary) Segmentation:
- Three-dimensional visualization of customer value
- Color-code segments by intervention strategies
- Track segment migration over time
Total impact: $12.7M incremental revenue in first year.
7. Democratized Data Access (Building Data Literacy at Scale)
The promise: Give everyone access to data and they’ll make better decisions. The reality: Give untrained people complex tools and they’ll either ignore them or make dangerous decisions based on misinterpreted data.
The democratization paradox: More access without more education creates chaos.
Bain research shows companies sharing data broadly outperform competitors—but successful democratization requires specific enabling conditions:
The Four Pillars of Successful Data Democratization:
- Graduated Access Levels: Executives get pre-built strategic dashboards; middle managers get interactive drill-down; frontline staff get role-specific views; analysts get full query access with governance controls
- Embedded Training: Data literacy fundamentals, tool-specific training, domain context, and ongoing office hours support
- Governed Self-Service: Certified datasets, semantic layers, pre-built calculations, usage monitoring
- Cultural Champions: Executive sponsorship, peer advocates, success stories, performance incentives
Manufacturing Example: A company with 18 factories moved from centralized reporting (3.2-day turnaround, 47 monthly ad-hoc requests) through uncontrolled self-service (22% adoption, conflicting analyses) to structured democratization with role-based dashboards and training.
Result: 82% adoption, 76% drop in ad-hoc requests, $3.2M in documented operational improvements.
When Big Data Visualization FAILS (What Nobody Tells You)
Failure Mode #1: Solution Seeking Problem
The Mistake: Implementing expensive visualization tools without clear business questions.
What Happens: Beautiful dashboards that nobody uses because they don’t answer actual questions.
Real Example: A logistics company spent $380K on Tableau enterprise deployment. After 6 months, the active user rate was 11%. Why? They built dashboards around available data, not business needs.
The Fix: Start with critical business questions: “Why are we losing customers in Q3 every year?” “Which products have the highest return rates and why?” Then identify data and visualizations needed to answer those questions.
Failure Mode #2: Garbage Data, Pretty Charts
The Mistake: Visualizing poor-quality data without cleaning it first.
What Happens: Decisions based on misleading patterns in flawed data.
Real Example: A retail client built sales dashboards showing declining performance in their fastest-growing region. After investigation: POS systems in that region had inconsistent time zone logging, making same-day comparisons meaningless.
The Fix: Audit data quality before visualization projects; build data quality monitoring into dashboards; show data freshness timestamps and completeness metrics; make data limitations transparent to users.
Failure Mode #3: Analysis Paralysis at Scale
The Mistake: Building dashboards with 50+ metrics and no prioritization.
What Happens: Users overwhelmed by choice, spend hours exploring without reaching conclusions.
Real Example: An insurance company created an underwriting dashboard with 83 different metrics across 12 tabs. Underwriters spent an average of 14 minutes per application navigating the interface—increasing processing time rather than decreasing it.
The Fix: Limit primary dashboards to 3-5 key metrics; use progressive disclosure (show summary, allow drill-down for detail); create “decision workflows” rather than “data exploration tools”; test dashboards with actual users before full rollout.
Failure Mode #4: Technical Debt Ignored
The Mistake: Building visualizations on fragile data pipelines that break frequently.
What Happens: Users lose trust when dashboards show stale or incorrect data.
Real Example: A SaaS company’s customer health dashboard relied on 7 different data sources with different update schedules. Any failure in the chain caused stale data, but the dashboard didn’t indicate which metrics were current. After the third incident of executives making decisions on outdated data, they stopped using it entirely.
The Fix: Invest in robust data infrastructure before flashy visualizations; implement monitoring and alerting for data pipeline health; build in circuit breakers (don’t display data older than X hours); show data freshness indicators prominently.
Looking Ahead: Where Visualization Technology Is Heading
Based on current trends and emerging technologies:
1. AI-Augmented Analytics (Already Here, Rapidly Improving)
What It Does:
- Automated insight generation (AI scans data, surfaces anomalies)
- Natural language query (“Show me declining products in Northeast region”)
- Automated narrative generation (AI writes summary of what changed and why)
- Predictive forecasting built into dashboards
Current Limitations:
- AI-generated insights are often obvious to domain experts
- Natural language understanding still imperfect
- Requires high-quality, well-structured data
- Black box explanations reduce trust
Prediction: Within 3-5 years, AI will handle 60-70% of routine dashboard creation. Analysts will focus on complex, ambiguous problems requiring human judgment.
2. Real-Time Collaborative Analytics (Emerging)
What It Enables:
- Multiple users exploring same dataset simultaneously
- Annotation and commenting on visualizations
- Shared cursor showing what colleagues are examining
- Live co-editing of dashboards
Current Examples: Figma proved collaborative design works. Analytics tools adopt similar patterns.
Prediction: Standard feature in all major BI platforms within 2-3 years.
3. Embedded Analytics Everywhere (Accelerating)
The Trend: Visualization embedded directly in operational systems rather than separate BI tools.
Examples:
- Salesforce dashboards embedded in CRM workflow
- Analytics built into manufacturing equipment control panels
- Financial data displayed in ERP transaction screens
Why It Matters: Reduces context-switching, increases data use at the moment of decision.
Prediction: Within 5 years, “opening a BI tool” will be uncommon—analytics will be ambient within all business applications.
Conclusion: Making It Work in Your Organization
Big data visualization delivers transformative advantages—but only when implemented thoughtfully with realistic expectations.
The companies succeeding with visualization share these characteristics:
- They start with clear business objectives, not technology fascination. They know which decisions they’re trying to improve before selecting tools.
- They invest in data infrastructure before flashy dashboards. They understand that visualization amplifies whatever quality of data you feed it.
- They design for actual users in their real workflows, not for demo presentations or executive vanity projects.
- They build data literacy alongside deploying tools, recognizing that access without education creates chaos rather than empowerment.
- They establish governance that balances flexibility with consistency, preventing the “wild west” of conflicting analyses.
- They measure outcomes, tracking not just dashboard usage but actual business decisions improved and dollars saved/earned.
If you’re considering big data visualization, ask yourself:
- Do you have the data infrastructure to support it?
- Do you have clear business questions it will answer?
- Are you prepared to invest in user training and change management?
- Do you have governance processes to prevent chaos?
- Can you commit to ongoing maintenance and evolution?
If yes, visualization will likely transform your organization. If no, address those gaps first—or your expensive project will join the graveyard of underutilized tools.
The competitive advantage goes to organizations extracting insights from data faster than competitors. Effective visualization makes that possible—but requires skill, discipline, and strategy to wield effectively.












{kind=link}
{kind=link}
{kind=link}
{kind=link}