
If you’ve ever found yourself staring at your company’s scattered data sources, wondering how to turn that chaos into actionable insights… you’re not alone.
From my experience helping dozens of mid-market companies modernize their data infrastructure, I’ve seen this same frustration play out countless times.
Business leaders know their data holds immense value, but they’re stuck with fragmented systems that make analytics feel like an uphill battle.
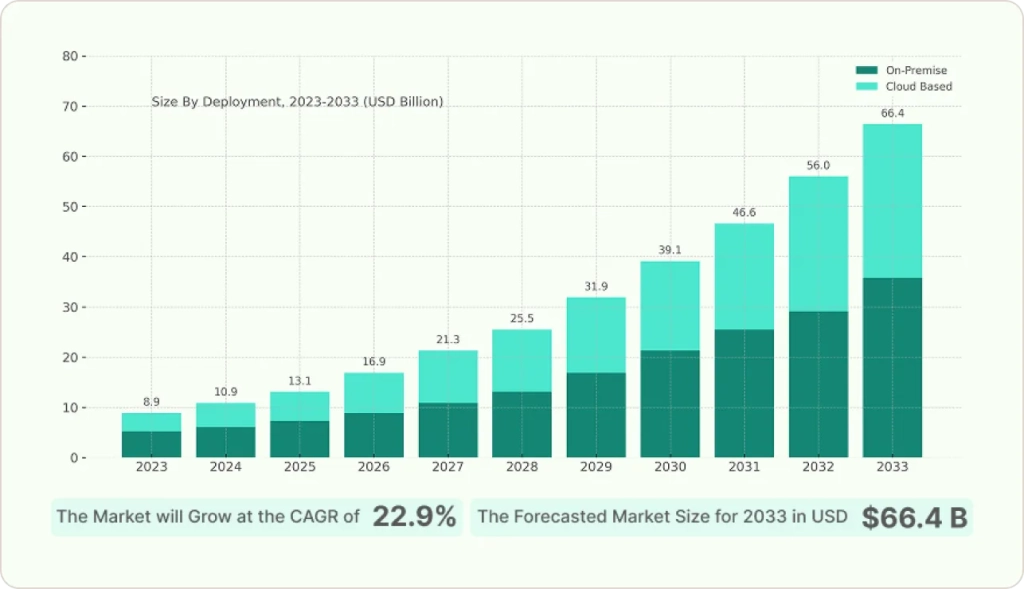
When I first started helping companies with their data lake vs data warehouse vs data lakehouse decisions back in 2018, the landscape was much simpler. But here’s what shocked me: the global data lake market was estimated at USD 13.62 billion in 2023 and is projected to grow at a CAGR of 23.8% from 2024 to 2030. Meanwhile, the data lakehouse market is exploding from USD 8.9 billion in 2023 to an estimated USD 66.4 billion by 2033.
The reality is that modern data warehouse architectures are evolving faster than ever. Over 328 million terabytes of data is generated every single day at present, with more than 181 zettabytes of data per year expected in 2025. Companies can no longer afford to choose the wrong data lakehouse architecture or stick with outdated approaches that create more silos than solutions.
In this guide, I’ll walk you through exactly how to navigate the data lake architecture, data warehouse architecture, and data lakehouse vs data warehouse decision. You’ll discover which approach aligns with your business goals, see real case studies from companies who got it right, and understand what modern enterprises are actually implementing in 2025.
Key Takeaways: Your Data Architecture Decision Guide
- Data warehouses excel at structured analytics and BI reporting but struggle with unstructured data and ML workloads
- Data lakes provide cost-effective storage for all data types but require significant governance investment to avoid becoming “data swamps”
- Data lakehouses combine the best of both worlds, offering structured analytics on flexible storage with ACID transactions
- Modern data warehouse implementations are shifting toward cloud-native, decoupled storage and compute architectures
- The right choice depends on your specific use cases: pure BI needs favor warehouses, ML-heavy workloads prefer lakes, unified analytics demands lakehouses
What is a Data Warehouse? The Foundation of Structured Analytics
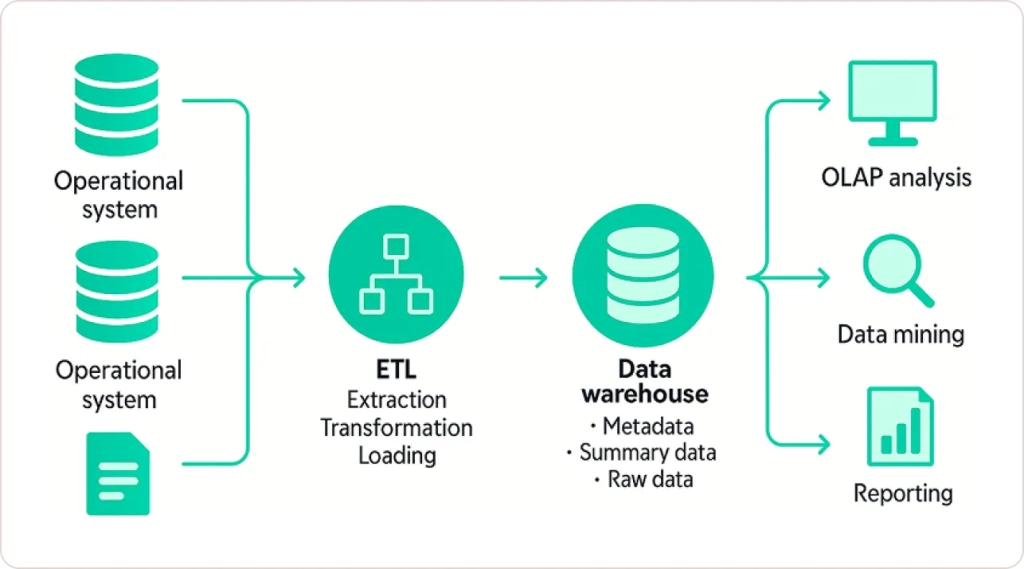
Let me be honest with you: when most business leaders think about data analytics, they’re actually thinking about data warehouse capabilities. A data warehouse is a centralized repository optimized for business intelligence and reporting, where data gets transformed and structured before storage.
Here’s what I’ve learned after years of implementing warehouse solutions: they’re incredibly powerful when your primary need is fast, consistent reporting on structured data. The data warehouse architecture typically includes:
Structured Data Processing: Everything follows predefined schemas and table structures. Your sales data, customer records, and financial transactions get cleaned, validated, and organized into dimensional models that make sense for analysis.
High-Performance Queries: Because data is pre-processed and indexed, complex analytical queries run blazingly fast. I’ve seen executive dashboards that would take hours to generate from raw data sources run in seconds from a well-designed warehouse.
Centralized Governance: Data warehouses enforce strict governance and security controls. Every piece of data has a clear lineage, and access controls ensure the right people see the right information.
Red flag alert: Traditional on-premise data warehouses had major limitations with fixed capacity and heavy upfront costs. That’s why modern data warehouse solutions have moved to the cloud.
The Modern Data Warehouse Revolution
Here’s the thing: according to Gartner infrastructure predictions, 65% of application workloads will be optimal or ready for cloud delivery by 2027, up from 45% in 2022. Cloud data warehouses like Snowflake, BigQuery, and Redshift have fundamentally changed the game by decoupling storage and compute.
What this means for your business: you can scale processing power independently from storage capacity, handle semi-structured data like JSON and XML, and support real-time analytics without the massive infrastructure investments of the past.
From my experience working with financial services companies, modern data warehouses shine when you need:
- Sub-second response times for executive dashboards
- Strict regulatory compliance and audit trails
- Consistent, reliable reporting across the organization
- Complex SQL-based analytics and business intelligence
Pro tip: Think of a modern data warehouse as your analytics command center. If 80% of your data needs revolve around structured reporting and BI, this is likely your best starting point.
What is a Data Lake? The Flexible Data Repository
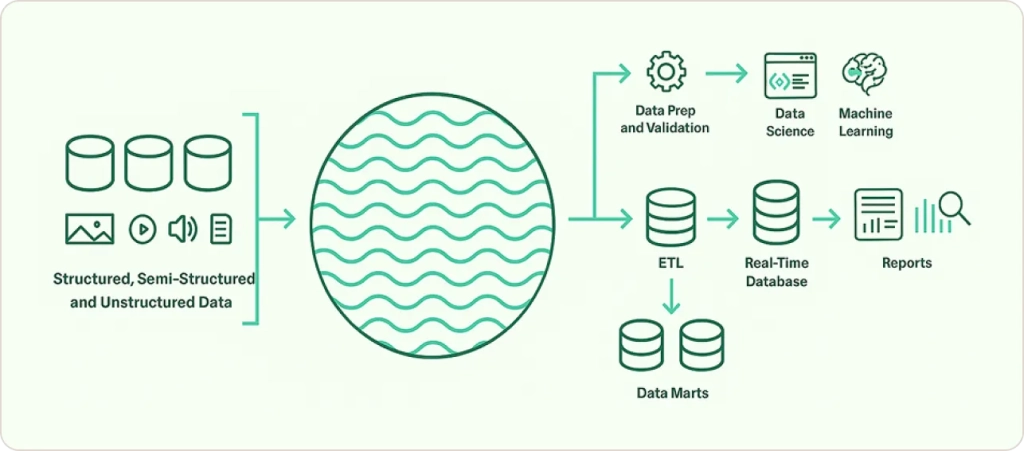
A data lake takes a completely different approach. Instead of forcing data into predefined structures, it stores everything in its native format and applies structure only when you read it (schema-on-read approach).
Here’s what I always ask clients considering data lake architecture: “Do you have diverse data sources generating unstructured content?” If you’re dealing with IoT sensor data, social media feeds, images, videos, log files, or any data that doesn’t fit neatly into database tables, a data lake might be your answer.
Key characteristics that make data lakes unique:
Unlimited Scalability: By leveraging cloud object storage like AWS S3 or Azure Data Lake Storage, you can store petabytes of data at a fraction of traditional database costs. I’ve worked with companies storing years of IoT sensor data that would have been prohibitively expensive in a traditional warehouse.
Data Type Flexibility: Store structured CSV files alongside unstructured text documents, images, videos, and streaming data. No upfront schema design required.
Cost-Effective Storage: Object storage typically costs pennies per gigabyte per month, making it economical to keep historical data that might have future analytical value.
Processing Engine Separation: Query engines like Apache Spark, Presto, or cloud-native services process data directly from storage, providing flexibility in how you analyze information.
The Data Lake Reality Check
Let me be honest with you: data lakes aren’t magic solutions. According to recent data architecture research, Data Quality issues have risen by 15 hours between 2022 and 2023, and in 2023 and beyond, 25% or more of revenue will be subjected to Data Quality issues.
Common data lake challenges I’ve observed:
Governance Complexity: Without careful management, data lakes become “data swamps” filled with unreliable, undocumented information that nobody trusts for business decisions.
Performance Trade-offs: Raw file scanning can be slower than optimized warehouse queries, especially for complex joins and aggregations.
Skills Requirements: Your team needs expertise in big data tools and distributed computing frameworks, which many traditional IT teams lack.
Non-negotiable: If you’re implementing a data lake, invest heavily in metadata management, data cataloging, and governance frameworks from day one. I’ve seen too many organizations struggle with lakes that became unmanageable over time.
What is a Data Lakehouse? The Best of Both Worlds
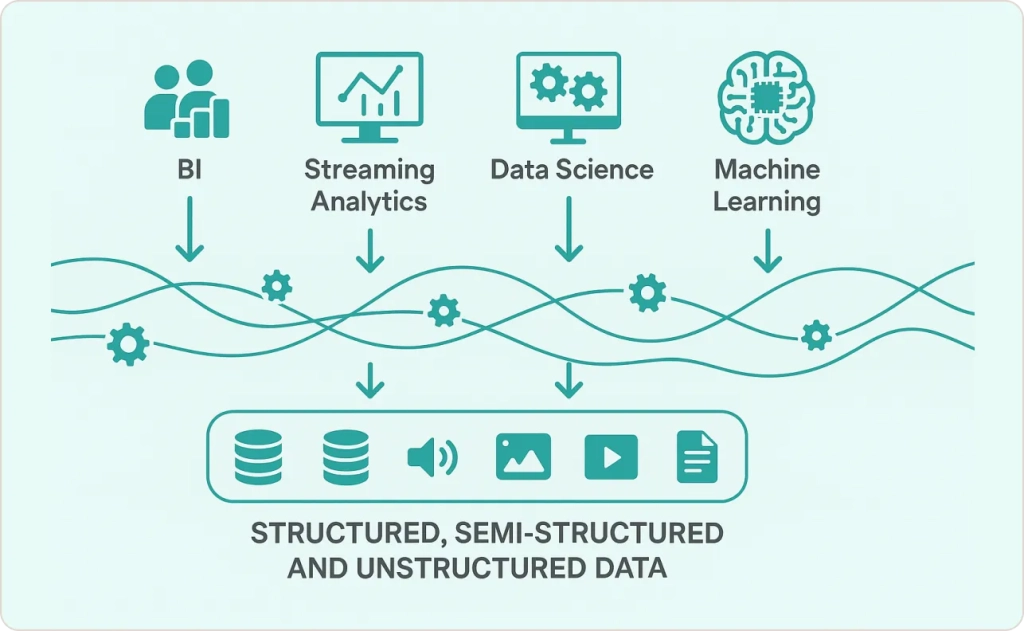
Now here’s where things get exciting. A data lakehouse represents the evolution of data architecture, combining the flexibility and cost-effectiveness of data lakes with the management features and performance of data warehouses.
When I first started seeing data lakehouse architecture implementations around 2020, I was skeptical. Another buzzword, I thought. But after helping several companies implement lakehouse platforms, I’ve become a true believer. Here’s why:
ACID Transactions on Raw Data: Lakehouses support atomicity, consistency, isolation, and durability (ACID) transactions directly on data stored in object storage. This means you get the reliability of a database with the flexibility of a lake.
Open Table Formats: Technologies like Apache Iceberg, Delta Lake, and Apache Hudi create a metadata layer that provides schema enforcement, versioning, and time-travel capabilities on your data lake storage.
Unified Analytics Platform: Run business intelligence, machine learning, and real-time analytics on the same dataset without moving data between systems.
Multi-Engine Support: Query the same data using SQL engines, Spark for machine learning, or streaming processors for real-time analytics.
Real-World Lakehouse Success
Here’s a case study that perfectly illustrates what is a data lakehouse in practice: According to AWS data modernization research, an AWS partner helped a large biotech firm modernize their Oracle data warehouse into a data lakehouse, resulting in a 10× increase in DataOps agility and a 15× boost in ML team productivity.
The biotech company’s challenge was classic: their legacy warehouse couldn’t scale for machine learning use cases, leading to data silos and poor data quality. The lakehouse solution eliminated ETL bottlenecks and provided real-time, high-quality data for both analytics and science workloads.
Another compelling example: 7bridges supply chain transformation shows how an AI-powered supply chain management platform replaced its relational databases with a data lakehouse to access data faster and streamline decision-making. Their growth had hit database architecture limits with slow queries and limited data access for non-technical users.
Voice of Experience: In practice, companies often use all three approaches: raw data lands in a lake, a lakehouse platform enriches and catalogs it, and a cloud warehouse/BI layer sits on top for dashboards. The key is integration and governance across them.
For organizations considering lakehouse implementation, our modern data platform consulting helps design unified architectures that maximize ROI while minimizing complexity.
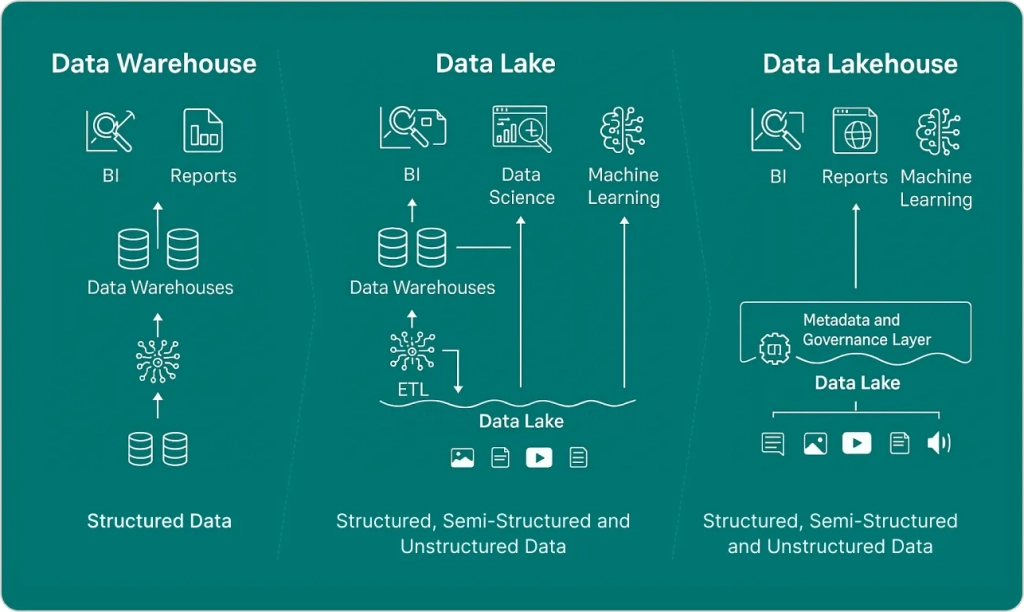
Data Lakehouse vs Data Warehouse: The Strategic Comparison
Let me break down the data lakehouse vs data warehouse decision with real business context. After helping dozens of organizations make this choice, here are the key differentiators that actually matter:
Flexibility and Data Variety
Data Warehouses: Excel with structured and semi-structured data but struggle with unstructured content like images, videos, or raw IoT streams. If your analytics needs center on traditional business data—sales, finance, operations—warehouses provide unmatched performance.
Data Lakehouses: Handle any data type while maintaining warehouse-like query performance through optimization layers. Perfect when you need to analyze customer sentiment from social media alongside traditional sales data.
Cost Structure and Scalability
Here’s what I’ve observed: data lakehouse architecture typically costs 40-60% less than traditional warehouse approaches for mixed workloads. According to McKinsey data transformation studies, legacy solutions cannot match the business performance, cost savings, or reduced risks of modern technology, with numerous banks achieving a 70 percent cost reduction from adopting data-lake infrastructure.
Performance and Query Speed: Modern data warehouse engines are still the gold standard for complex SQL analytics. However, advanced lakehouse implementations with proper indexing and caching can match warehouse performance for most use cases.
Data Freshness and Real-Time Analytics
Data Lakehouses provide a significant advantage here. Without copying data from lake to warehouse, lakehouses can provide fresher data by ingesting in real-time and applying changes directly in the lake, reducing lag.
Understanding real-time requirements is crucial for architecture decisions. Our guide on real-time analytics implementation provides detailed frameworks for evaluating streaming vs. batch processing needs.
Governance and Compliance: Both approaches support enterprise-grade governance, but lakehouses extend these capabilities to all data types, not just structured information.
Data Lakehouse vs Data Lake: Why Structure Matters
The data lakehouse vs data warehouse comparison gets most of the attention, but the data lake distinction is equally important. Here’s what I tell clients about why structure matters:
Schema Management
Data Lakes: Assume any format (schema-on-read), making analytics more complex and error-prone. Without careful governance, you’ll spend more time cleaning data than analyzing it.
Data Lakehouses: Enforce schemas at write time while allowing evolution over time. This prevents the “garbage in, garbage out” problem that plagues many lake implementations.
Transaction Safety
Data Lakes: Concurrent writes can cause corruption without careful coordination. I’ve seen critical analytics fail because multiple processes tried to update the same dataset simultaneously.
Data Lakehouses: ACID transactions ensure multiple users and engines can safely read and write data without conflicts.
Query Performance
Raw data lakes require scanning entire files for queries, which can be painfully slow for large datasets. Data lakehouse architecture includes indexing, caching, and partition pruning that dramatically improves query performance.
Modern Data Architecture Trends Shaping 2025
According to Gartner’s data analytics trends, as AI and automation take center stage, CIOs and CDOs must rethink their approach to data governance, accessibility, and decision-making. Here are the trends I’m seeing that will impact your modern data warehouse and lakehouse decisions:
AI-Driven Data Management
According to DATAVERSITY’s 2025 analysis, with increased AI and machine learning tools central to processing data in real time, pressure to use these technologies will grow as organizations give over 40% of their core IT spending to AI by 2025.
What this means for your architecture: you need platforms that can support both traditional analytics and machine learning workloads without data movement or duplication.
Cloud-Native Everything
According to McKinsey digital transformation research, companies that want their next-generation data products to be successful may need to revise their data architecture and data governance. Cloud providers are driving innovation with:
- Serverless analytics that scale automatically
- Separation of storage and compute for cost optimization
- Native integration with machine learning and AI services
- Real-time streaming capabilities built into the platform
Data Mesh and Decentralized Architectures
Data mesh is a data management approach that supports a domain-led practice for defining, delivering, maintaining and governing data products. Forward-thinking organizations are implementing domain-driven data architectures where business units own their data products.
Edge Computing Integration
According to Gartner’s edge AI predictions, Gartner predicts that more than 55% of all data analysis by deep neural networks will occur at the point of capture in an edge system by 2025, up from less than 10% in 2021.
Evaluating how these trends impact your specific industry and use cases requires deep expertise. Our technology roadmap consulting helps organizations align data architecture decisions with long-term business strategy and emerging technology trends.
Industry Use Cases: Which Architecture Fits Your Business?
From my experience across different sectors, here’s how data lake architecture, data warehouse architecture, and data lakehouse architecture map to real business needs:
Financial Services: Compliance Meets Innovation
Traditional Banking: Stick with modern data warehouse solutions for core regulatory reporting, risk management, and customer analytics. The structured approach and audit trails are non-negotiable.
Fintech and Digital Banking: Data lakehouse architecture enables real-time fraud detection, personalized financial products, and advanced analytics on diverse data sources including social media and alternative credit data.
Case Study: According to data lakehouse innovation research, European banks are leveraging Data Lakehouses for real-time fraud detection. One major bank reported a 40% reduction in false positives for fraud alerts after implementing a Data Lakehouse solution.
Healthcare: Structured Records Meet Unstructured Research
Clinical Operations: Data warehouse architecture for patient records, billing, and operational reporting ensures HIPAA compliance and fast query performance.
Research and Population Health: Data lakehouse platforms combine electronic health records with genomic data, medical imaging, and research datasets. Healthcare analytics research found that hospitals using Data Lakehouse architectures saw a 22% improvement in patient outcomes for chronic diseases.
For healthcare organizations navigating compliance requirements while modernizing analytics, our healthcare data solutions provide HIPAA-compliant architectures that accelerate research and operational insights.
Manufacturing: IoT Sensors Meet Business Intelligence
Production Analytics: Modern data warehouse for supply chain management, quality control reporting, and financial analytics.
Predictive Maintenance: Data lake or lakehouse for storing massive IoT sensor datasets, machine logs, and predictive maintenance algorithms. According to McKinsey manufacturing analytics, in Japan, automotive manufacturers are using Data Lakehouses to analyze sensor data from production lines in real-time, leading to a 15% increase in production efficiency.
Retail: Customer 360 and Omnichannel Analytics
Traditional Retail Analytics: Data warehouse for sales reporting, inventory management, and financial analytics.
Digital Commerce: Data lakehouse architecture unifies online behavior, in-store purchases, social media engagement, and supply chain data. Retail analytics case studies show Australian retailers are using Data Lakehouses to create unified customer profiles, resulting in a 30% increase in cross-sell opportunities.
Understanding your specific industry requirements is crucial for architecture success. Explore our industry-specific solutions to see how different sectors are implementing modern data architectures.
Common Pitfalls and How to Avoid Them
Let me be honest with you: I’ve seen brilliant data architecture strategies fail because of avoidable mistakes. Here are the red flags I watch for:
Pitfall 1: Technology-First Thinking
The Problem: Choosing lakehouse, warehouse, or lake based on vendor marketing rather than business requirements.
The Solution: Start with use cases and work backward to technology. If you can’t articulate the specific business value, don’t start the project.
Pitfall 2: Underestimating Governance Requirements
The Problem: According to enterprise governance studies, about 54% of executives have made Data Governance a top priority for 2024 to 2025, but many implementations treat governance as an afterthought.
The Solution: Design data governance, security, and metadata management into your architecture from day one. The cost of retrofitting governance is 5-10x higher than building it in initially.
Learn more about implementing robust governance frameworks in our comprehensive data governance strategy guide.
Pitfall 3: Ignoring Skills and Change Management
The Problem: Implementing sophisticated data lakehouse architecture without training teams or adjusting operational processes.
The Solution: Plan for 6-12 months of skills development and process changes. Your architecture is only as good as the people operating it.
Pitfall 4: Trying to Do Everything at Once
Warning: I’ve seen organizations attempt to modernize everything simultaneously and end up with partially implemented systems that satisfy nobody.
Pro tip: Implement in phases, prove value with each step, and build momentum through early wins rather than comprehensive overhauls.
The Future of Data Architecture: What’s Coming Next
Based on my work with innovative companies and industry research, here’s what I see shaping the next generation of modern data warehouse and lakehouse implementations:
AI-Native Architectures
According to GenAI architecture research, GenAI lives on unstructured data—text, images, videos, audios—as the most abundant source for generating new insights. Future architectures will be designed primarily for AI workloads, with traditional analytics as a secondary consideration.
Real-Time Everything
The batch processing paradigm is dying. According to streaming analytics trends, as the need for real-time data processing continues to grow, data lakehouses will likely place a greater emphasis on supporting real-time data processing and analytics.
Simplified Governance
Automated data governance, powered by AI, will eliminate much of the manual effort currently required to maintain data quality and compliance.
Edge Integration
Edge computing will bring analytics closer to data sources, reducing latency and enabling new use cases in IoT, autonomous vehicles, and real-time decision-making.
Stay ahead of these emerging trends with our technology innovation insights and strategic planning resources.
Making Your Decision: Data Lake vs Data Warehouse vs Data Lakehouse
Here’s my framework for making the data lake vs data warehouse vs data lakehouse decision:
Choose a Modern Data Warehouse if:
- 80%+ of your analytics involve structured business data
- You need sub-second query performance for executive dashboards
- Regulatory compliance requires strict data lineage and governance
- Your team has strong SQL skills but limited big data experience
Choose a Data Lake if:
- You’re primarily focused on machine learning and data science
- Cost-effective storage of diverse data types is your priority
- You have strong technical teams comfortable with big data tools
- Real-time BI and reporting aren’t critical requirements
Choose a Data Lakehouse if:
- You need both traditional BI and advanced analytics capabilities
- Data variety includes structured, semi-structured, and unstructured sources
- You want to eliminate data silos and duplication
- Long-term scalability and flexibility are priorities
Red flag alert: Don’t choose based on what’s trendy or what vendors are pushing. Choose based on your specific use cases, team capabilities, and business requirements.
Conclusion: Building Your Data-Driven Future
The data lake vs data warehouse vs data lakehouse decision will fundamentally shape your organization’s analytics capabilities for the next 5-10 years. According to McKinsey future enterprise research, the data-driven enterprise of 2025 will be characterized by rapidly accelerating technology advances, the recognized value of data, and increasing data literacy.
What I’ve learned after helping dozens of companies navigate this decision: start with your most critical use cases, implement incrementally, and don’t be afraid to evolve your architecture as your needs change. The companies that succeed are those that view data architecture as a strategic capability, not just a technology project.











